开端:新智元 【新智元导读】奥特曼萧疏地承认了我方犯下的‘历史失实’,LeCun发文痛批硅谷一大常见病——错位优厚感。DeepSeek的终极兴致在哪?圈内热转的这篇分析指出,比拟R1,R1-Zero具有更遑急的商讨价值,因为它冲突了终极的东说念主类输入瓶颈! DeepSeek再度创造历史。 果真能逼得OpenAI CEO奥特曼承认:‘咱们在开源/怒放权重AI模子方面,一直站在了历史的失实一边。’ LeCun也发文指出,硅谷圈子的常见病,即是一种错位的优厚感。 高等阶段的症状,是合计小圈子就能把...
开端:新智元

【新智元导读】奥特曼萧疏地承认了我方犯下的‘历史失实’,LeCun发文痛批硅谷一大常见病——错位优厚感。DeepSeek的终极兴致在哪?圈内热转的这篇分析指出,比拟R1,R1-Zero具有更遑急的商讨价值,因为它冲突了终极的东说念主类输入瓶颈!
DeepSeek再度创造历史。
果真能逼得OpenAI CEO奥特曼承认:‘咱们在开源/怒放权重AI模子方面,一直站在了历史的失实一边。’
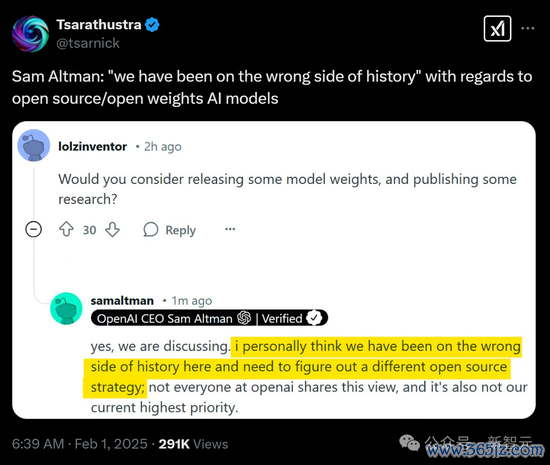
LeCun也发文指出,硅谷圈子的常见病,即是一种错位的优厚感。
高等阶段的症状,是合计小圈子就能把持好的想法。而晚期症状即是,假定来自他东说念主的翻新皆是靠舞弊。
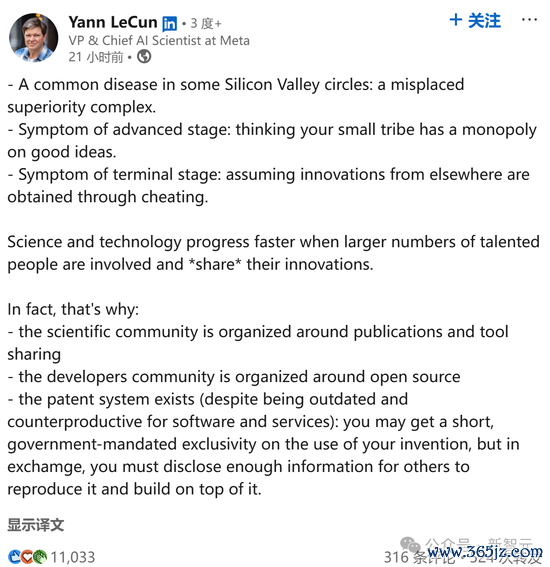
DeepSeek的最大兴致在那里?
ARC Prize连合首创东说念主Mike Knoop发出长文中总结说念——R1-Zero冲突了最终的东说念主类输入瓶颈——各人CoT标注!其中一个例子,即是监督微调(SFT)。
从R1-Zero到AGI,一切皆与效力联系。
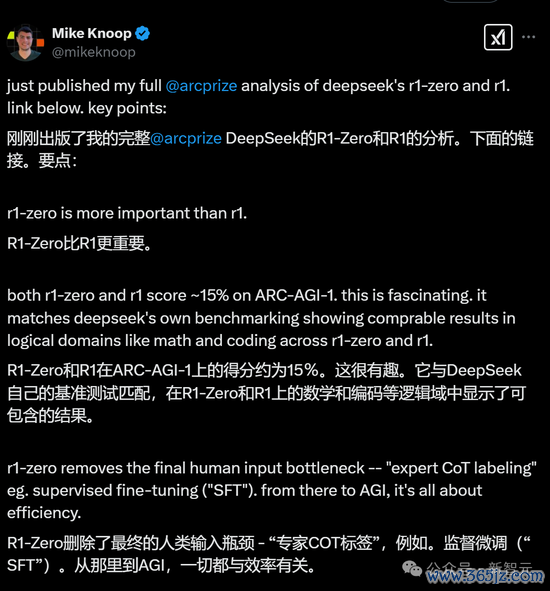
另一个值得珍视的不雅点即是:比拟R1,R1-Zero具有更遑急的商讨价值。
这是因为,R1-Zero豪阔依赖强化学习(RL),而不使用东说念主类各人标注的监督微调(SFT)。
这就标明,在某些界限,SFT并非结束准确明晰CoT的必要条款,豪阔有可能让AI通过纯粹的RL轮换结束平凡推理材干。
以下为Mike Knoop的竣工分析。
从此,推理预计需求激增
上周,DeepSeek发布了他们新的R1-Zero和R1‘推理’系统,在ARC-AGI-1基准测试上的阐扬可与OpenAI的o1系统相忘形。
R1-Zero、R1和o1(低算力款式)皆取得了15-20%的得分,而GPT-4o仅为5%——而这已是多年纯LLM scaling的巅峰效果。
根据本周好意思国商场的响应,公众也初始归拢了纯LLM scaling的局限性。
然则,大多数东说念主仍没挑升志到推理预计需求行将激增的问题。
2024年12月,OpenAI发布了一个新的突破性系统o3,经过考证,该系统在低算力款式下得分76%,高算力款式下得分88%。
o3系统初度展示了预计机在靠近全新、未知问题时进行适合的通用材干。
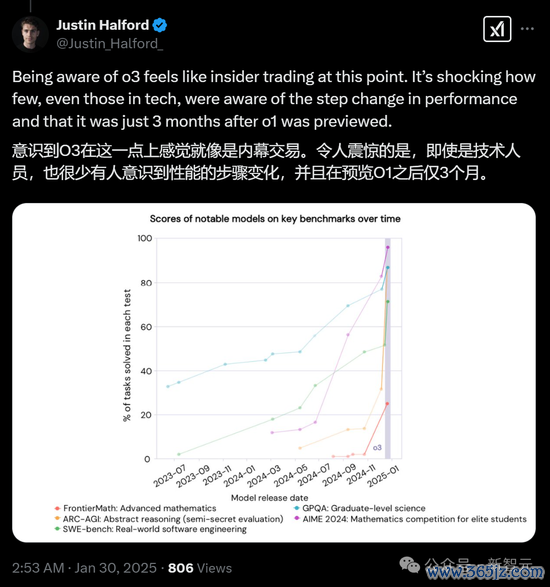
尽管o3在ARC-AGI-1基准测试中取得了突破性的收获,但这一科技大事件却在主流媒体中险些未被报说念,也未引起平凡眷注。
这是AI和预计机科学界限的一个极其遑急的时候,这些系统值得深化商讨。
然则,由于o1和o3是闭源的,咱们只可依靠推测进行分析。
运道的是,借助ARC-AGI-1,以及当今(险些)开源的R1-Zero和R1,咱们未必进一步加深对这一界限的归拢。
这里的‘险些’指的是,DeepSeek并未公布从零初始复现其模子权重的轮换。
极端值得珍视的是,比拟R1,R1-Zero具有更遑急的商讨价值。
R1-Zero比R1更值得分析:它摈斥了东说念主为瓶颈
在对o1和o3的分析中,ARC Prize团队对这些推理系统的责任道理进行了推测。
它们的裂缝想路如下:
为特定问题界限生成想维链(CoT)。
使用东说念主工各人(‘监督微调’SFT)和自动化机器(‘强化学习’RL)的组合对中间的CoT身手进行标注。
运用(2)中标注的数据查验基础模子。
在测试时,模子会基于这一推理历程进行迭代推理。
下图回来了用于各模子用于迭代采样的本领,偏激在ARC-AGI-1评分的联系情况。
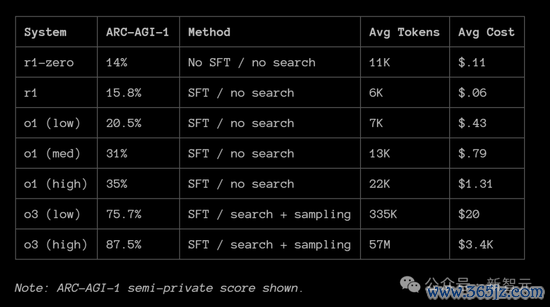
跟着DeepSeek发表的新商讨,ARC Prize团队就不错更好地考证我方的推测。
一个裂缝的发现是,LLM推理系统在适合新颖性(以及提高可靠性)方面的援助,主要沿着以下三个维度伸开:
为CoT历程模子的查验添加东说念主工标注,即SFT(监督微调)。
使用CoT搜索而非线性推理(即每个身手并行进行CoT推理)。
进行举座CoT采样(即并行推理所有轨迹)。
第(1)点受到东说念主工数据生成的适度,因此决定了哪些界限的推理系统能从中受益最大。
举例,在o1系统上,MMLU中的专科法律类目得分远低于数学和逻辑类目,这令东说念主颇感不测。
第(2)和(3)点的主要瓶颈在于预计效力。
o1和o3皆在ARC-AGI-1基准测试上阐扬出对推理预计量的对数式校正,即它们在测试时使用越多的预计资源,基准准确率就越高。
同期,不同的预计神志会影响这条弧线在x轴上的位置。
ARC Prize团队合计,DeepSeek最道理的作念法是单独发布了R1-Zero。R1-Zero不使用SFT(即不依赖东说念主工标注),豪阔依赖强化学习(RL)。
R1-Zero和R1在ARC-AGI-1上的得分高度一致,辩别为14%和15%。
此外,DeepSeek我方发布的基准测试收尾也标明R1-Zero和R1的阐扬周边,举例在 MATH AIME 2024上的得分辩别为71%和76%(比拟之下,基础模子DeepSeek V3的得分仅为约40%)。
在论文中,R1-Zero的作家指出:‘DeepSeek-R1-Zero在可读性较差和话语搀和等方面存在挑战’,这少量也在相聚上得到了印证。
然则,在ARC Prize团队的测试中,他们却险些莫得发现R1-Zero在ARC-AGI-1上阐扬出不连贯性,而这一测试任务与该系统通过强化学习查验的数学和编程界限相似。
概述这些发现,ARC Prize团队得出了以下论断:
在具有强可考证性的界限,SFT(即东说念主工各人标注)并非结束准确且明晰的 CoT(想维链)推理的必要条款。
R1-Zero的查验历程未必通过RL优化,在token空间内自愿构建里面的特定界限话语(DSL,Domain-Specific Language)。
SFT在援助CoT推理的跨界限泛化材干方面是必要的。
这少量安妥直观,因为话语本色上亦然一种推理DSL。疏浚的‘词’不错在一个界限中学习,并在另一个界限中应用,就像模范相通。

而纯RL轮换面前尚未未必发现一个平凡分享的词汇体系,这可能会成为改日商讨的一个遑急标的。
最终,R1-Zero展示了一种潜在的延长旅途——即使在查验数据相聚阶段,也豪阔摈斥了东说念主工瓶颈。
不错细则的是,DeepSeek 的意见是挑战OpenAI的o3系统。
接下来的裂缝不雅察点在于:SFT是否仍然是CoT搜索和采样的必要条款,或者是否不错构建一个访佛‘R2-Zero’的系统,在疏浚的对数式推理预计延长弧线上不时援助准确率。
根据R1-Zero的现实收尾,团队合计,在这种假定的延长版块中,SFT并不是越过ARC-AGI-1所必需的条款。
用更多资金,换取AI的可靠性
从经济角度来看,AI界限正在发生两大遑遽变化:
参加更多资金,以取得更高的准确性和可靠性。
查验资本正在向推理资本转化。
这两点皆将极地面鼓舞推理预计的需求,同期也不会扼制对更强预计资源的需求,反而会进一步增多预计需求。
AI 推理系统的价值,远不啻于提高基准测试中的准确率。
现时拒绝AI更平凡自动化应用(即推理需求)的紧要问题,即是可靠性。
ARC Prize团队曾与数百位试图在业务中部署AI智能体的Zapier客户交流过,他们的反馈高度一致:‘我还不信任它们,因为它们的责任阐扬不够默契。’
以前,ARC Prize曾建议,朝着ARC-AGI标的的进展将援助AI可靠性。
LLM智能体的主要挑战在于,它们需要强有劲的土产货界限收敛才能默契运行。
而更强的泛化材干,要求AI未必适合全新的、未见过的情况。如今,已有凭据标明这一不雅点是正确的。
因此,Anthropic、OpenAI、Apple等多家公司纷纷推出AI智能体也不及为奇。

由于可靠性需求,智能体将鼓舞短期内的推理预计需求增长。
此外,援助者不错选拔参加更多预计资源,以提高用户对系统的信任度。
然则,更高的可靠性并不料味着100%的准确性——但它能让失实愈加默契、可展望。
这反而是可接管的,因为当准确率较低时,用户和援助者不错通过辅导词更默契地指引 AI当作。
以前被合计预计机无法科罚的问题,如今皆不错用财富估量其科罚资本。跟着AI预计效力的援助,这些资本也将慢慢下跌。
推理即查验:AI数据获取范式或将历久鬈曲
另一个正在发生的遑遽变化,是用于LLM预查验的数据开端。
以前,大多数查验数据要么是购买的,要么是从相聚爬取的,要么是由现存的LLM合成生成(举例蒸馏或数据增强)。
但推理系统提供了一种全新的选拔——生成‘信得过’数据,而非传统兴致上的‘合成’数据。
AI行业频繁将‘合成数据’视为质地较低的数据,这些数据频繁是通过LLM轮回生成的,只是是为了增多查验数据的总体限制,但其收益会慢慢递减。
如今,借助推理系统和考证器,咱们不错创造全新的、有用的数据来进行查验。这不错通过两种神志结束:
离线生成 ——援助者支付用度来创建数据。
推理时生成 ——结尾用户支付用度来创建数据。
这是一种引东说念主翔实的经济款式鬈曲,可能会导致AI系统援助者之间出现‘赢家通吃’的所在。
领有最多付用度户的AI公司将领有浩瀚的数据把持上风,因为这些用户在无形中资助了新高质地数据的创建,而这些数据反过来又进一步援助模子材干,使其更受用户嗜好……由此造成一个自增强的良性轮回。
若是咱们未必突破东说念主类各人CoT标注的瓶颈,并构建一个极高效的搜索/合成+考证系统来自动生成新数据,那么不错猜度,改日将会有大量预计资源参加到这些推理系统中。
因为这些系统的查验效果将平直与资金参加和数据输入量挂钩,也即是说,惟有参加资金和原始数据,模子就会变得更强。
最终,这种AI查验款式将透彻取代基于东说念主类生成数据的预查验轮换。

论断:DeepSeek鼓舞全天下科学发展
跟着推理需求的增长变得愈加明确,商场将不时资格调养。
AI 系统的效力援助不仅会鼓舞更多的应用,这不仅安妥杰文斯悖论,更遑急的是,更高的预计效力解锁了全新的查验范式。
跟着R1的开源和可复现性,越来越多的个东说念主和团队将探索CoT和搜索本领的极限。
这将匡助咱们更快地厘清现时AI商讨的前沿在那里,并鼓舞一波本领翻新波澜,从而加快通向 AGI的程度。
也曾有几位商讨者告诉ARC Prize团队,他们规画在2025年ARC奖中使用R1格调的系统,这让东说念主极端期待看到最终的收尾。
R1的开源,对所有天下来说皆是一件善事。DeepSeek鼓舞了科学的前沿发展,并为AI 商讨带来了新的突破。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
包袱裁剪:何俊熹 kaiyun体育网页版登录